Enabling Peer-to-Peer Traffic with NoLoad® NVMe Computational Storage and P2PDMA
- Written by: Andrew Maier
Since the early days of P2PDMA in Linux kernel 4.20, enabling Peer-to-Peer (P2P) traffic has been a focus for Eideticom. In the age of AI applications and large datasets, efficiently moving stored data closer to processing has become increasingly important. The P2PDMA framework enables seamless data movement between PCIe devices without burdening host memory. As a fully open-source solution integrated into the upstream Linux kernel, it offers distinct advantages over competing proprietary technologies like GPUDirect [1].
Recently, there have been two significant development advances for P2PDMA in the kernel community. The development of a new userspace interface has been accepted upstream as of kernel v6.2 [2] which allows user applications to allocate and use P2PDMA memory. Most notably, this interface, alongside the entire kernel framework, has been enabled by default in Ubuntu 24.04 (Noble Numbat) [3] and adoption by other major distributions such as RHEL is on the horizon.
Host CPUs can utilize an NVMe Controller Memory Buffer (CMB) as a Direct Memory Access (DMA) target for P2P traffic. CMB is a region of memory exposed as a PCIe Base Address Register (BAR) by an NVMe compliant device. The available CMB exposed by all NoLoad NVMe Computational Storage products allows P2PDMA to be used without code changes by user applications running on modern kernels.
This post will outline the architecture of the P2PDMA framework and provides performance results gathered using standard in-box Linux tools while describing the test server setup. Potential applications of the CMB within the NoLoad framework will also be explored, offering insights into the tangible benefits of this cutting-edge technology.
Background of P2PDMA
Figure 1 shows the difference between traditional (legacy) DMAs and DMAs using P2PDMA.
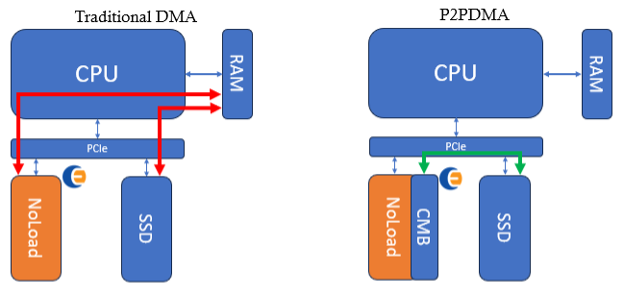
Figure 1: Traditional DMAs vs P2PDMA. This shows how the P2PDMA framework can entirely avoid the system memory (RAM)
Transfers that use the P2PDMA framework bypass the system memory (RAM) and instead use an exposed PCIe memory (such as the CMB of an NVMe compliant NoLoad device). In memory intensive applications, the system memory performance can become a bandwidth and latency bottleneck – the use of P2PDMA avoids this problem by moving data directly between peer PCIe devices. This functionality is available on modern root ports and CPU processors.
NVMe CMB integration into P2PDMA, like NVIDIA’s GPUDirect Storage, promises streamlined data processing and acceleration between NoLoad accelerators and storage devices.
NoLoad CMB Test
The test setup utilizes a server setup with Ubuntu 24.04, 4x PCIe Gen4 SSDs, and a NoLoad with a 512 MiB CMB implemented on a Bittware IA-440i Agilex-7 FPGA card. Figure 2 shows a block diagram of the server setup.
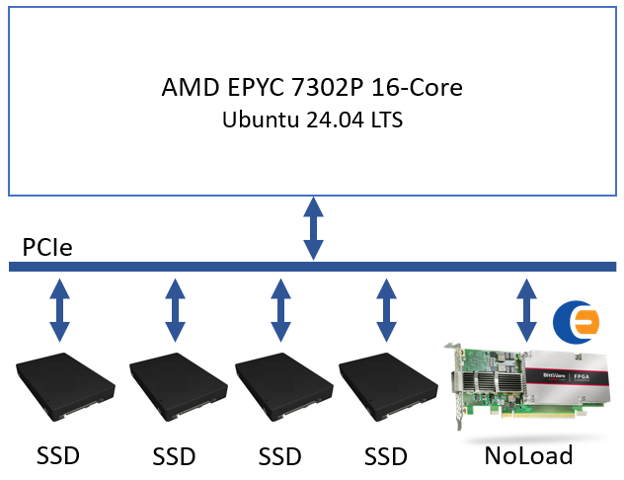
Figure 2: Block diagram showing the NoLoad P2PDMA test setup
Server: Lenovo ThinkSystem SR635 1U
CPU: AMD EPYC 7302P 16-Core Processor
System Memory: 512 GB (8 x 64 GB Lenovo DDR4 3200MHz ECC)
OS: Ubuntu 24.04 LTS (6.8.0-31-generic)
SSDs: 4x Samsung MZQL23T8HCLS-00A07 U.2 PCIe Gen4x4
NoLoad: Bittware IA-440I Agilex-7 AIC w/ 512MiB NVMe CMB
Traffic was generated from the DMA engines of the SSDs that targeted the CMB of the NoLoad using P2PDMA by a one-line FIO config change enabling the iomem option [4]. This gave the results in Figure 3.
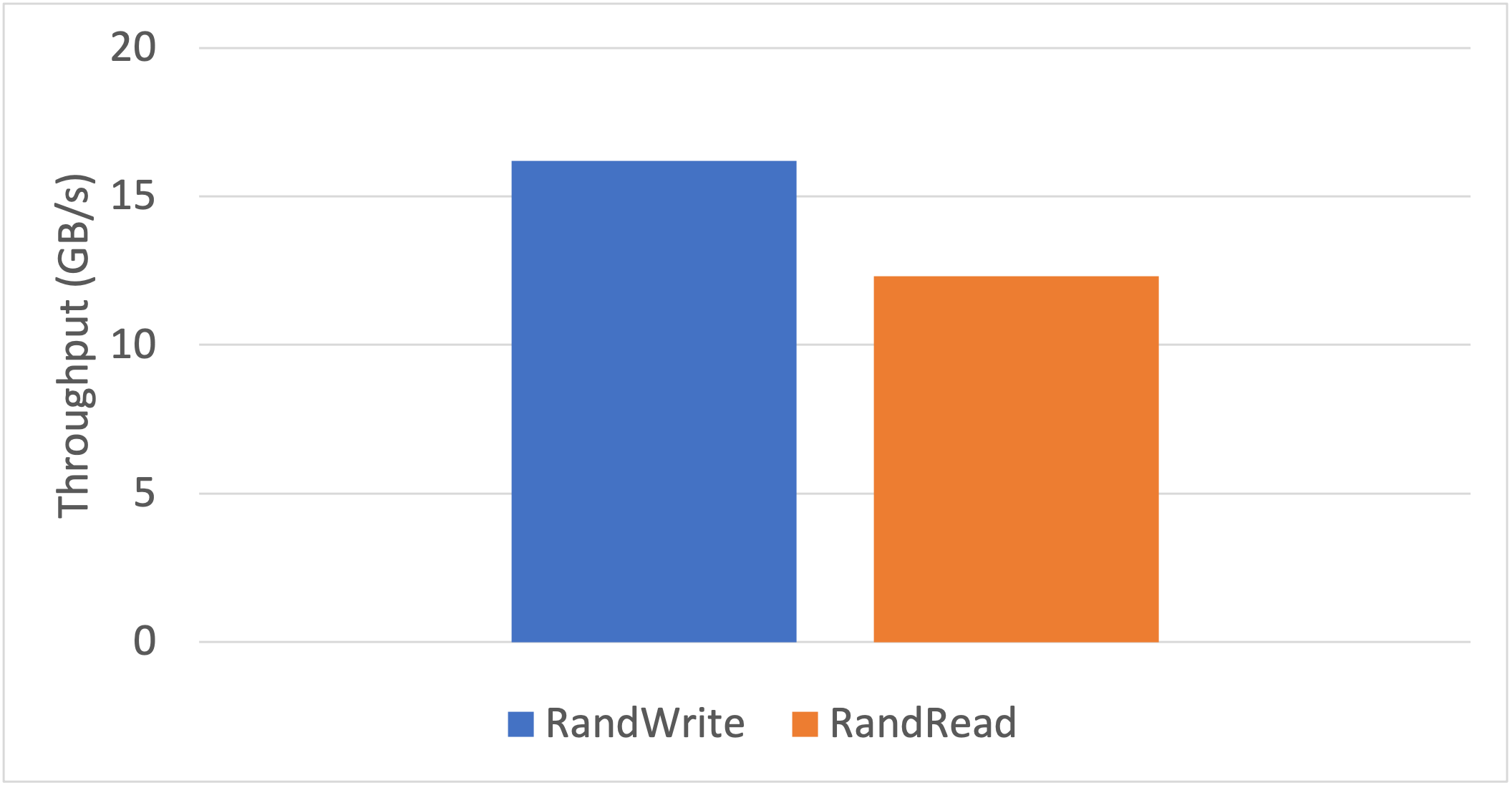
Figure 3: Performance results of DMA transfers between 4 SSDs and the NoLoad CMB.
The maximum random write throughput from the SSDs to the NoLoad CMB via P2PDMA was measured to be 16.3 GB/s. The maximum random read performance from the NoLoad CMB to the SSDs was measured to be 12.6 GB/s. Note, reads and writes are from the perspective of the CMB.
The maximum throughput performance of the P2PDMA test was limited by the dual DDR4 banks on the IA-440I card, not by the P2PDMA framework. This result shows that high bandwidth data transfers between SSDs and the NoLoad CMB can be achieved without using system memory, freeing up the bandwidth for other tasks.
Conclusion
In summary, P2PDMA, now enabled by default in Ubuntu 24.04, provides an open-source, vendor-neutral alternative to proprietary solutions (such as GPUDirect) for transferring data without utilizing system memory. The full functionality of upstream open-source P2PDMA was demonstrated by this test using NoLoad’s NVMe Compliant CMB.
Testing demonstrated the ability to achieve high bandwidth data transfers between storage devices and NoLoad while entirely avoiding the system memory of the CPU.
Takeaways
- By leveraging the P2PDMA framework, which is in upstream Linux and enabled by default in Ubuntu 24.04 LTS, PCIe traffic between devices can be offloaded completely from system memory. Now there is an upstream, open-source, and vendor-neutral solution for enabling P2P data transfers!
- Eideticom’s NoLoad NVMe Computational Storage Processor (CSP) provides an NVMe complaint CMB, enabling P2PDMA transfers with exceptional performance.
- Utilizing P2PDMA with NoLoad enables the direct pipelining of accelerator functions with data provided to/from SSDs, thereby alleviating the load on system memory and optimizing data flow.
Next Steps
In upcoming blog posts, we will explore further applications, such as integrating with a network card (NIC), pipelining acceleration functions, and implementing the NoLoad CMB in High Bandwidth Memory (HBM).
Contact Eideticom (
References
|
[1] |
"GPU Direct," [Online]. Available: https://developer.nvidia.com/gpudirect. |
|
[2] |
"Peer-to-peer DMA," [Online]. Available: https://lwn.net/Articles/931668/. |
|
[3] |
"Ubuntu Launchpad," [Online]. Available: https://bugs.launchpad.net/ubuntu/+source/linux-oem-6.0/+bug/1987394. |
[4] FIO config:
[global]
runtime=1h
time_based=1
group_reporting=1
ioengine=libaio
bs=1M
iomem=mmapshared:/sys/class/nvme/nvme2/device/p2pmem/allocate
iodepth=16
direct=1
zero_buffers=1
[p2p-read]
rw=read
numjobs=16